概率定义
有如下常用公式
P(A∪B)=P(A)+P(B)−P(AB)P(AB)=P(A∪B)=1−P(A∪B)
条件概率
条件概率公式
P(B∣A)=P(A)P(AB)
经过变形,可以得到乘法公式
P(AB)=P(A)P(B∣A)
全概率公式
P(A)=P(B1)P(A∣B1)+P(B2)P(A∣B2)+...+P(Bn)P(A∣Bn)
独立事件
若两个事件相互独立,则
P(AB)=P(A)P(B)
一维
泊松分布
是二项分布的极限
设X∼B(n,p),λ=np,则
P(X=k)=e−λk!λkP(X≤n)=k=0∑ne−λk!λk
指数分布
概率密度函数为
f(x)={λe−λx,x>00,otherwise
分布函数为
F(x)=1−e−λx
正态分布
定义
f(x)=2πσ1e−2σ2(x−μ)2X∼N(μ,σ2)
分布函数
标准正态分布的分布函数记为Φ(x),有表可查。
F(x)=Φ(σx−μ)P(a<X<b)=F(b)−F(a)=Φ(σb−μ)−Φ(σa−μ)P(X>a)=1−F(a)=1−Φ(σa−μ)Φ(−x)=1−Φ(x)
随机变量转换
已知fX(x)和Y=g(X),则Y的概率密度函数为
fY(y)=fX[h(y)]∣h′(y)∣,α<y<β
其中h(y)是g(x)的反函数
二维
二维随机变量的分布函数为
F(x,y)=P(X≤x,Y≤y)
离散型
独立性
若二维随机变量相互独立,则
P(X≤x,Y≤y)=P(X≤x)P(Y≤y)
即可以得到联合分布律与但变量分布律的关系
F(X,Y)=FX(x)FY(y)
若P(X=xi,Y=yj)=P(X=xi)P(Y=yj), 即pij=pi.p.j
连续型
独立性
-
第一种方法
f(x,y)=fX(x)fY(y)
另外由f(x,y)=fX(x)fY∣X(y∣x) ,可知若相互独立,则
fY(y)=fY∣X(y∣x)fX(x)=fX∣Y(x∣y)
-
第二种方法
f(x,y)=r(x)g(y)and:fX(x)=∫−∞+∞r(x)dxr(x)=r(x)∫−∞+∞g(y)dyfY(y)=∫−∞+∞g(y)dyg(y)=g(y)∫−∞+∞r(x)dx
-
推论
若U=u(x),V=v(x)
FUV(u,v)=FU(u)FV(v)
举例来说,若X,Y相互独立,则aX+b,cY+d也相互独立
边缘分布律
二维随机变量X,Y关于某一分量的边缘分布函数指X或Y作为一元随机变量时的分布函数,
FX(x)=P(X≤x),FY(y)=P(Y≤y)FX(x)=P(X≤x,Y<+∞)=F(X,+∞)
不等式
P(∣X∣≥a)≤akE(∣X∣k)
数字特征
数学期望
离散型:
P(X=xk)=pk,k=1,2,...E(X)=k=1∑+∞xkpkifY=g(X):E(g(X))=k=1∑+∞g(xk)pk
连续性:
E(X)=∫−∞+∞xf(x)dxifY=g(X):E(g(X))=∫−∞+∞g(x)f(x)dx
二维连续型:
E(X)=∫−∞+∞∫−∞+∞xf(x,y)dxdyE(Y)=∫−∞+∞∫−∞+∞yf(x,y)dxdyE(g(X,Y))=∫−∞+∞∫−∞+∞g(x,y)f(x,y)dxdy
常见数学期望表:
| 分布 |
期望 |
| 0-1分布 |
p |
| B(n,p) |
np |
| P(λ) |
λ |
| 均匀分布 |
2a+b |
| E(λ) |
λ1 |
| N(μ,σ) |
μ |
性质:
E(aX)=aE(x)E(X+Y)=E(X)+E(Y)E(i=1∑nXi)=i=1∑nE(Xi)
如果X和Y相互独立
E(XY)=E(X)E(Y)
方差
概念
D(X)=E((X−E(X))2),即随机变量X的取值偏离平均值的平均偏离程度
离散型变量:
P(X=xk)=pk,k=1,2,...D(X)=k=1∑+∞(xk−E(X))2pk
连续型变量:
D(X)=∫−∞+∞(x−E(X))2f(x)dx
常用公式
D(X)=E(X2)−E2(X)
常用方差表
| 分布 |
方差 |
| 0-1分布 |
p(1−p) |
| B(n,p) |
np(1−p) |
| P(λ) |
λ |
| 均匀分布 |
12(b−a)2 |
| E(λ) |
λ21 |
| N(μ,σ) |
σ2 |
性质
D(aX)=a2D(X)D(aX+b)=a2D(X)D(aX±bY)=a2D(X)+b2D(Y)±2abE((X−E(X))(Y−E(Y)))=D(X)+D(Y)±2ab(E(XY)−E(X)E(Y))=D(X)+D(Y)±2abcov(X,Y)
如果X和Y相互独立,则有
D(X±Y)=D(X)+D(Y)D(i=1∑naiXi)=i=1∑nD(aiXi)=i=1∑nai2D(Xi)
协方差
定义
试图定义一种新的量,来反映随机变量(X,Y)之间的某种联系
cov(X,Y)=E((X−E(X))(Y−E(Y)))=E(XY)−E(X)E(Y)
相关系数:
ρXY=D(X)D(Y)cov(X,Y)
若相关系数为0,则称(X,Y)不相关
性质
cov(aX,bY)=abcov(X,Y)cov(X+Y,Z)=cov(X,Z)+cov(Y,Z)
中心极限定理
对于随机分布序列X1,X2,...,Xn,无论X服从什么分布,当n足够大时,Xi均服从正态分布
且对于Yn=Y(X1,X2,...Xn),有
D(Yn)Yn−E(Yn)∼N(0,1)n→∞limP(D(Yn)Yn−E(Yn)≤y)=Φ(y)
注意σ是标准差,σ2是方差
若对∀Xi,P(Xi=1)=p,即服从0-1分布,那么
Yn=i=1∑nXi∼B(n,p)Yn∼N(np,np(1−p))
统计量分布
常用统计量
样本均值
X=n1i=1∑nXi
样本方差
S2=n−11i=1∑n(Xi−X)2
k阶原点矩
Ak=n1i=1∑nXik
k阶中心矩
Bk=n1i=1∑n(Xi−X)k
常用统计量有如下一些结论。设E(X)=μ,D(X)=σ2
E(X)=μ=E(X)D(X)=nσ2=nD(X)
另外,对于样本方差和2阶中心矩有如下结论:
S2=n−1nSn2Sn2=n1i=1∑n(Xi−X)2=n1i=1∑n(Xi2−2XiX+X2)=n1(i=1∑nXi2−2Xi=1∑nXi+i=1∑nX2)=n1(i=1∑nXi2−2nX2+nX2)=n1(i=1∑nXi2−nX2)=n1i=1∑nXi2−X2∴E(Sn2)=E(n1i=1∑nXi2)−E(X2)=n1i=1∑nE(Xi2)−[D(X)+E2(X)]=n1i=1∑n(σ2+μ2)−nσ2−μ2=σ2+μ2−nσ2−μ2=nn−1σ2∴E(S2)=n−1nnn−1σ2=σ2D(S2)=D[σ2(n−1)S2n−1σ2]=(n−1σ2)2D(σ2(n−1)S2)=(n−1σ2)2D(χ2(n−1))=(n−1σ2)2(2n−2)=n−12σ4D(Sn2)=D(nn−1S2)=(nn−1)2n−12σ4=n22(n−1)σ4
样本均值
若总体X服从正态分布N(μ,σ2),那么从中抽取样本量为n的样本X1,X2,...,Xn的样本均值X
X=n1i=1∑nXi
也服从正态分布,且
X∼N(μ,nσ2)
其他统计量的分布
-
χ2分布
若X1,X2,...,Xn是来自正态总体N(0,1)的样本,则统计量χ2
χ2=i=1∑nXi2χ2∼χ2(n)E(χ2(n))=n,D(χ2(n))=2n
对于样本方差S2,满足:
σ2(n−1)S2∼χ2(n−1)∵S2=n−11i=1∑n(Xi−X)2∴σ21i=1∑n(Xi−X)2∼χ2(n−1)
-
t分布
若X∼N(0,1),Y∼χ2(n),X,Y相互独立,则统计量T
T=Y/nXT∼t(n)
-
F分布
若X∼χ2(m),Y∼χ2(n),且X,Y相互独立,则统计量F
F=Y/nX/mF∼F(m,n)
F(m,n)的α分位数Fα(m,n)有表可查
P(F≤Fα(n,m))=αF1−α(n,m)=Fα1(m,n)
点估计
矩估计法
即用样本矩来估计总体矩
求解过程:
E(X)=n1i=1∑nXi=XE(X2)=D(X)+E2(X)=n1i=1∑nXi2
联立(1)(2)两式,其中E(X),E(X2)均用未知量表示,最终解得的结果是关于X和Xi的函数
真搞懂啦~
极大似然估计法
-
求解过程:
宗旨是让L尽可能大
假设X符合的分布有与θ1,θ2,...,θk有关,x1,x2,...,xn是X的一组样本值
-
写出似然函数L
-
对L求的多个参数依次求偏导,一般来说可以对lnL求偏导。
L(x1,x2,...,xn;θ1,θ2,...,θk)=i=1∏nf(xi;θ1,...,θk)∂θj∂lnL=0,r=1,2,...,k
-
根据以上求得的极大似然估计值,求极大似然估计量,即用X替换x
若L对于θ不是可微的或偏导数=0无解,那么要考察θ与L的相关性。
若θ越大L越大,则θ取能取到的最大值
若θ越大L越小,则θ取能取到的最小值
或根据f(x)中x的范围确定θ
-
不变性原理
若θ^是θ的极大似然估计值,那么u(θ)=u(θ^))
点估计的评价方法
无偏性
对于总体参数θ,若其估计量为θ^,且
E(θ^)=θ
称θ^是θ的无偏估计量
有效性
设θ^1和θ^2都是总体参数θ的估计量,若
D(θ^1)<D(θ^2)
称θ^1比θ^2更有效
- 主要运用方差的性质进行计算
- 算数均值是所有线性无偏估计中方差最小的
一致性
也称“依概率收敛”,具体表示为:若当n→∞时,θ^→θ,即
x→∞limP{∣θ^−θ∣≥ϵ}=0
更常用的形式是
x→∞limP{∣θ^−θ∣<ϵ}=1
具体做题时,可借助切比雪夫不等式:
P{∣X−E(X)∣<ϵ}≥1−ϵ2D(X)
如果可证θ^的无偏性,那么
1≥P{∣θ^−θ∣<ϵ}≥1−ϵ2D(X)
在应用夹逼定理,即可证极限为1
区间估计
对于一个正态总体X∼N(μ,σ2)
- σ2已知,μ的置信区间,置信度1−α
Z=nσ2X−μ∼N(0,1)P(∣Z∣≤z2α)=1−αP(X−z2αnσ<μ<X+z2αnσ)=1−α
- σ2未知,μ的置信区间
T=nS2X−μ∼T(n−1)P(∣T∣≤t2α(n−1))=1−αP(X−t2α(n−1)nS<μ<X+t2α(n−1)nS)=1−α
- μ已知,σ2的置信区间
Q=i=1∑n(σXi−μ)2∼χ2(n)P(χ2α2(n)<Q<χ1−2α2(n))=1−αP(χ2α2(n)∑i=1n(Xi−μ)2<σ2<χ1−2α2(n)∑i=1n(Xi−μ)2)=1−α
- μ未知,σ2的置信区间
K=σ2(n−1)S2∼χ2(n−1)P(χ2α2(n−1)<K<χ1−2α2(n−1))=1−αP(χ2α2(n−1)(n−1)S2<σ2<χ1−2α2(n−1)(n−1)S2)=1−α
假设检验
单个总体均值
α的含义:X−μ0的值非常大(小),大到其发生的概率只有α。α通常只有0.05或0.01
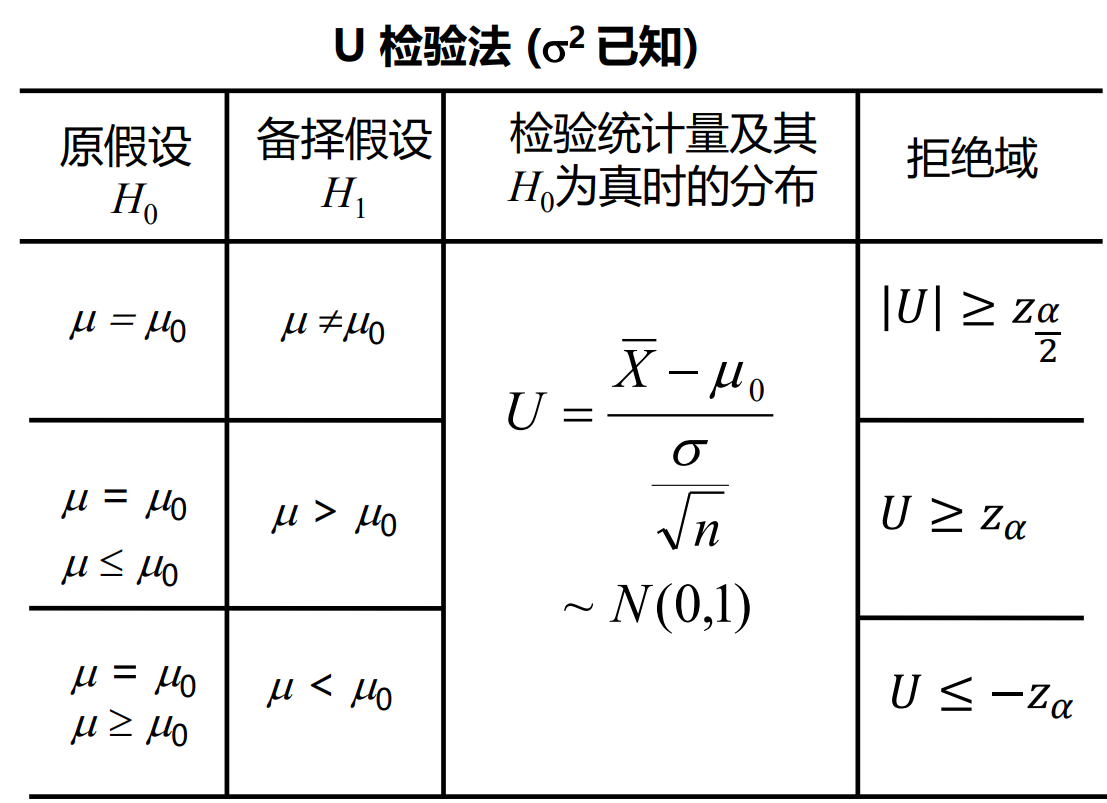
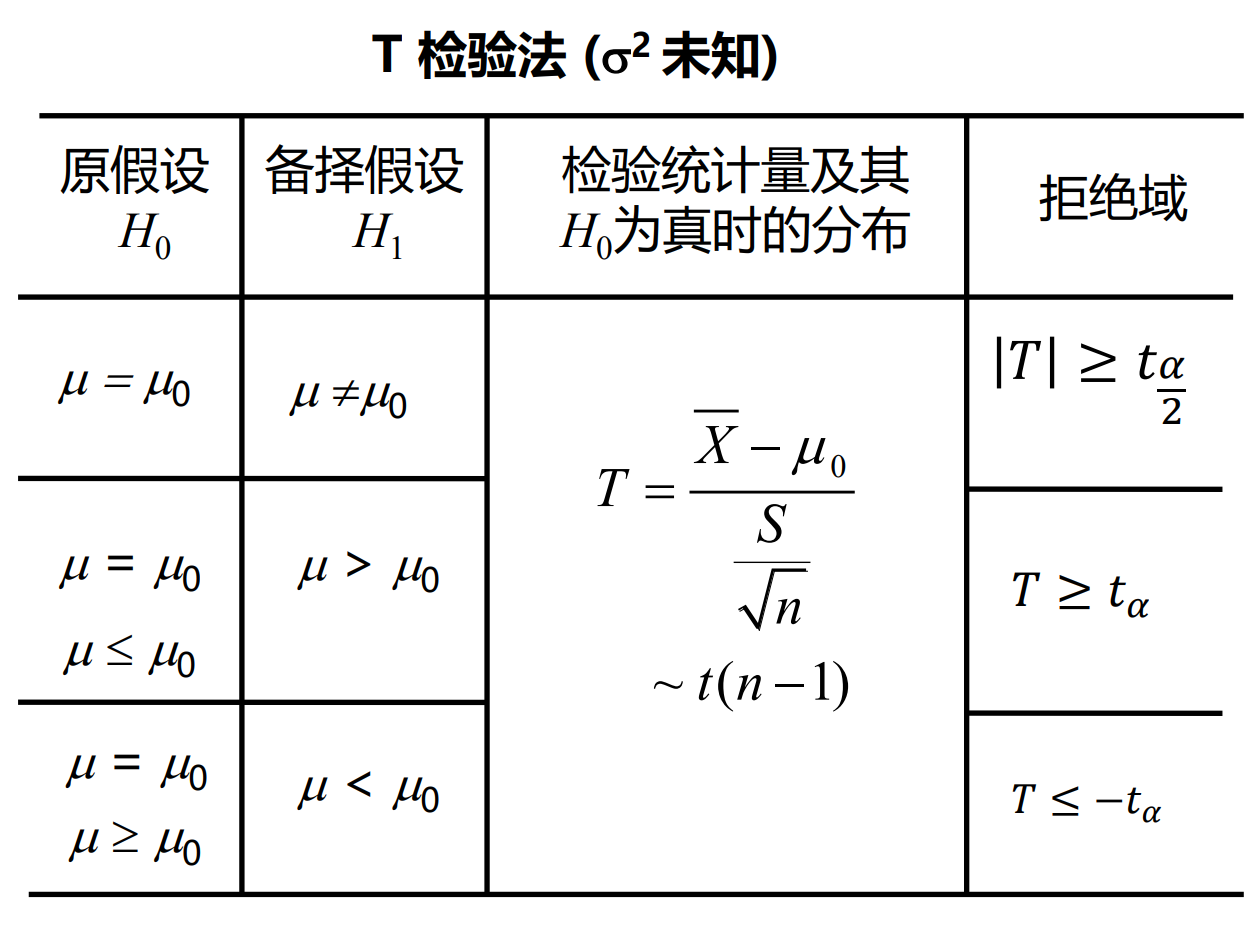
两个总体均值
设样本X有n1个,Y有n2个,且来自的总体的方差均为σ2,那么检验统计量变为
t=Swn11+n21X−Y
其中Sw2为两个总体方差的加权平均
Sw2=n1+n2−2(n1−1)S12+(n2−1)S22
拒绝与可参照上面两个表格
单个总体方差
σ02S2非常大(小),大到其发生的概率只有α。α通常非常小,只有0.01或0.05
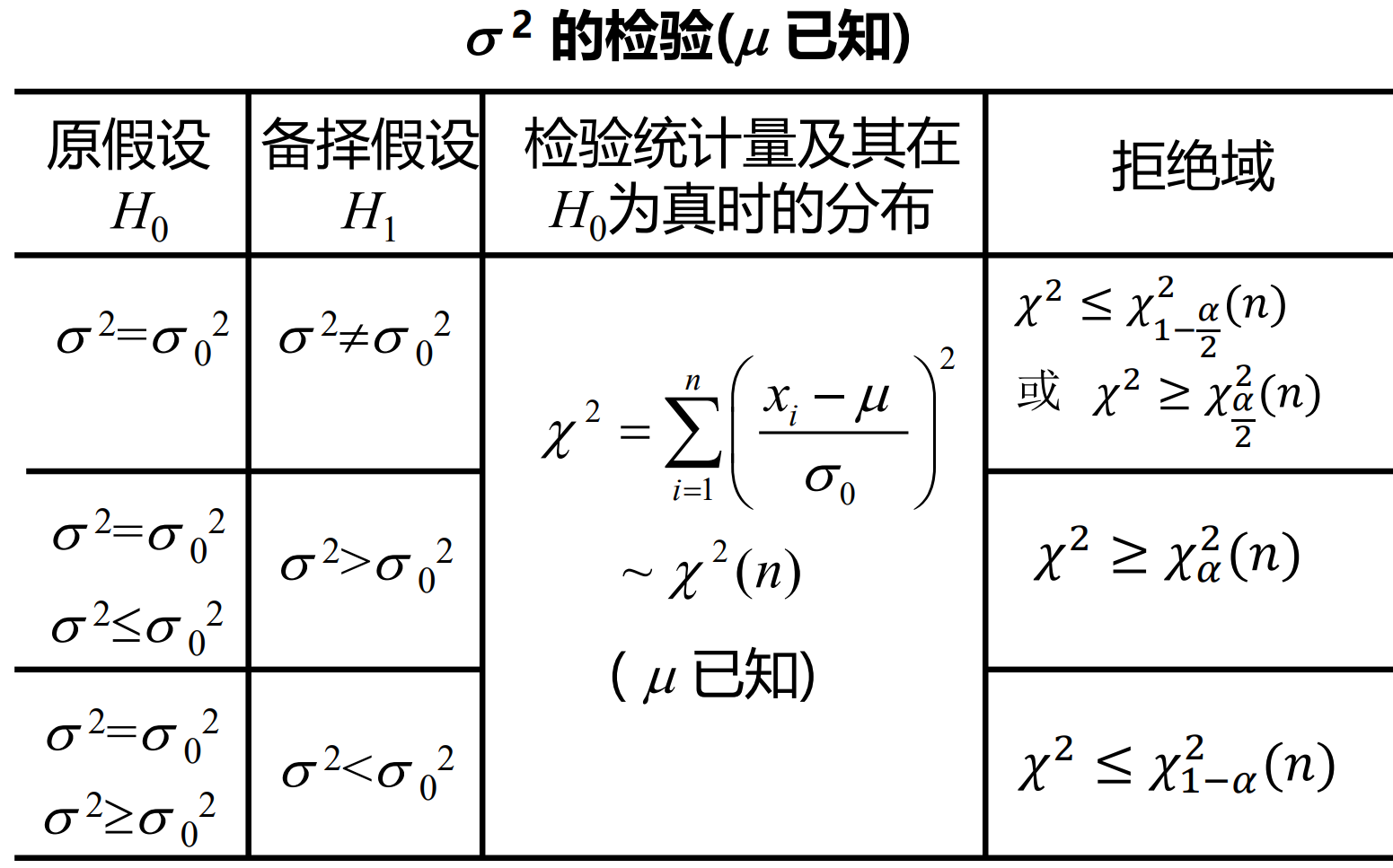

例题
-
将4个可区分的球随机的放入4个盒子,求空盒子数量的数学期望
设X为空盒子数量,Xi为第i个盒子是否为空。可得X=X1+X2+X3+X4。
对于Xi,
P(Xi=1)=(43)4P(Xi=0)=1−(43)4∴E(Xi)=(43)4
因此
E(X)=E(i=1∑4Xi)=i=1∑4E(Xi)=4×(43)4
数学期望
-
设在 [0, 1] 中随机地取两个数 X,Y , 求D(minX,Y)
要明确minX,Y也是g(X,Y)的一种形式,因此应该先求出(X,Y)的联合分布律,在按计算E(g(X,Y))的方法进行计算
-
相互独立与不相关
若X,Y相互独立,则P(X<x,Y<b)=P(X<x)P(Y<y)
若X,Y不相关,则cov(X,Y)=0
在正态分布与特殊均匀分布中,独立等价于不相关
